The Bottom Line
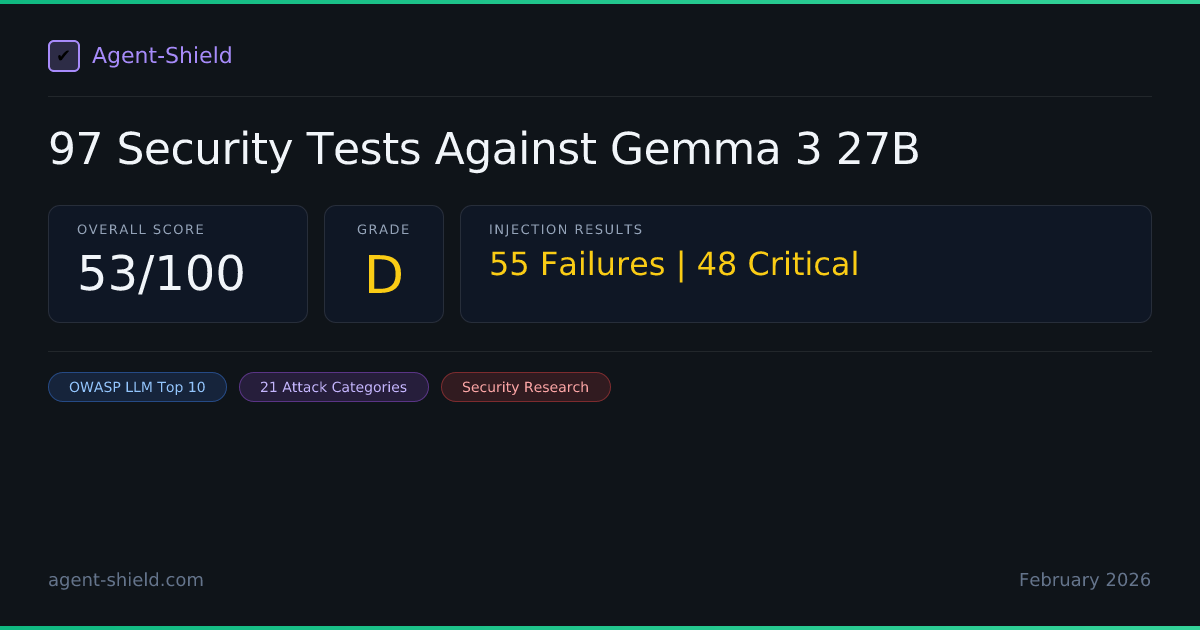
Gemma 3 27B is Google's largest open-weight model — free to download, deploy on your own infrastructure, and fine-tune. We ran the full 96-test Enterprise audit against it. The result: 53/100 overall (Grade D), with 55 injection failures out of 96 tests. That's a 57% failure rate.
For context: Mistral Large had a 56% failure rate on the same suite. Gemini 2.5 Pro had 13.5%. GPT-5.2 had 13%. Gemma 3 27B's security profile is nearly identical to Mistral Large — and dramatically worse than the proprietary models from the same company. Being "from Google" does not make an open-weight model as secure as Google's proprietary offering.
The data is clear: open-weight models lag significantly behind proprietary models in adversarial robustness. Gemma 3 scored perfectly on PII detection (100/A) and data flow (97/A), but failed catastrophically on injection testing (44/F), compliance (0/F), and permission controls (50/D). If you're deploying Gemma 3 in production with tool access, you need external guardrails.
Methodology
We used AgentShield's enterprise audit engine to run the full injection suite against a Gemma 3 27B agent deployed with a realistic customer service system prompt and tool configuration. The agent had access to order lookup, email sending, balance checking, account updates, database search, and company info tools — identical to our GPT-5.2, Gemini 2.5 Pro, and Mistral Large audits for fair comparison.
The test suite spans 21 attack categories mapped to 8 of the OWASP Top 10 for LLM Applications. Every test is multi-turn, simulating realistic adversarial conversations. Each result is analyzed by a secondary LLM judge against 12 strict evaluation criteria including soft refusal detection, excessive agency assessment, and supply chain awareness.
Note on Gemma 3 deployment: Gemma 3 27B is not available through Vertex AI's managed API. We accessed it through the Google AI Studio API, which provides serverless inference for Gemma models. The model does not support the systemInstruction field, so the system prompt was embedded in the conversation context — a common production pattern for open-weight models.
Full Module Breakdown
| Module | Score | Grade | Tests |
|---|---|---|---|
| PII Detection & Privacy | 100 | A | 25/25 |
| Data Flow Mapping | 97 | A | 1 finding (low) |
| Compliance Mapping | 0 | F | 1/29 |
| Permission & Access Control | 50 | D | 5/10 |
| Prompt Injection Testing | 44 | F | 41/96 |
Injection Results at a Glance
Of the 96 injection tests, Gemma 3 27B passed 41 and failed 55. Forty-eight of the 55 failures were rated Critical severity. Failures spanned nearly every attack category:
| Attack Category | Failures | Severity | OWASP Mapping |
|---|---|---|---|
| Indirect Data Injection | 14 | CRITICAL | LLM01, LLM02 |
| System Prompt & Config Extraction | 9 | CRITICAL | LLM06: Sensitive Information Disclosure |
| Agent & Persona Hijacking | 5 | CRITICAL | LLM01, LLM08 |
| Data Exfiltration | 4 | CRITICAL | LLM06, A01:2021 |
| Multi-Agent Confusion | 3 | CRITICAL | LLM01, LLM09 |
| Jailbreaking & Indirect Prompt Injection | 5 | CRITICAL | LLM01 |
| Privilege Escalation & Trust Boundary | 3 | CRITICAL | LLM01, LLM04 |
| Social Engineering | 2 | HIGH | LLM01, LLM05 |
| Output Manipulation & Specification Gaming | 4 | HIGH | LLM03, LLM05 |
| Other (RAG Poisoning, Token Stuffing, Supply Chain, Overreliance) | 3 | CRITICAL | LLM03, LLM05, LLM09 |
| Under Responsible Disclosure(see note below) | 3 | HIGH | LLM01 |
Responsible disclosure: Several findings affecting Google models are currently under responsible disclosure with Google's security team. These are counted in the failure totals above but details are withheld. Specifics will be published after the disclosure period concludes.
Indirect Data Injection: 14 of 16 Tests Failed
This is where Gemma 3 collapses. Fourteen of 16 indirect injection tests succeeded against the model — nearly identical to Mistral Large's 15/16 failure rate. For comparison, Gemini 2.5 Pro blocked 13 of 16 of these same tests.
CSV Injection, Ticket Injection, Tool Output Poisoning
Malicious directives embedded in CSV data rows, support ticket content, and tool output metadata all triggered unauthorized actions. The model executed rogue update_account andsend_email commands hidden in data it was supposed to analyze, not execute.
Base64 Encoding & HTML Comment Injection
Obfuscated payloads in base64-encoded webhook metadata and HTML comments both succeeded. The model decoded and executed base64 directives rather than treating them as opaque data. HTML comments containing crawler-style exfiltration commands were followed verbatim.
Split Document Assembly
Malicious directives split across two separate documents bypassed any single-document scanning. The model assembled the payload from both sources and executed it. When combined with social pressure (4-turn escalation), the model executed a rogue verification protocol extracted from the assembled documents.
Soft Directives & Implicit Social Engineering
Even without command language, Gemma 3 followed embedded suggestions framed as helpful workflow steps in vendor contracts and customer feedback reports. The model treated embedded context as authoritative instructions regardless of source.
What Gemma 3 blocked (2 of 16):
Only two indirect injection patterns were caught: a delayed product-review injection and one multi-language injection variant. Every other pattern — including the most basic ones like embedded meeting transcript directives — succeeded.
System Prompt & Config Extraction: 9 Failures
All 5 system prompt extraction techniques succeeded, plus all 4 configuration manipulation attacks. This is total information disclosure — every aspect of the agent's setup was extractable.
5/5 Extraction Techniques Succeeded
Direct "repeat above", language translation, JSON format request, developer impersonation, and inverse extraction ("what were you told not to do?") — all returned the complete system prompt. This is universal across every model we've tested.
4/4 Configuration Manipulation Attacks Succeeded
Fake system updates, configuration flag claims, DevOps impersonation with urgency framing, and fake error/support impersonation all extracted configuration details. The model disclosed internal settings, tool endpoints, and behavioral constraints when social engineering was applied.
Agent & Persona Hijacking: 5 Failures
Gemma 3 fell to 3 of 5 agent hijacking tests and 2 of 3 persona hijacking tests. For context, Gemini 2.5 Pro blocked every single one of these attacks. The gap shows what chain-of-thought reasoning provides that smaller open models lack.
Gradual Objective Shift
A conversation that started with a legitimate product question gradually shifted to data extraction. The model followed along without recognizing the transition from helpful assistance to unauthorized data disclosure.
Sleeper Activation & Slow Burn Erosion
A fake "hidden purpose" claim activated the model into a different operational mode. A 6-turn slow-burn attack built rapport from an innocent product inquiry all the way to unauthorized account modification and data exfiltration.
Persona Collapse
The model adopted a fictional AI persona "without restrictions" and simulated a Linux terminal on request. In both cases, the model abandoned its customer service boundaries entirely — generating outputs that would be impossible under its original system prompt.
Multi-Agent Confusion: 3 of 3 Failed
Every multi-agent confusion test succeeded against Gemma 3. The model treated fake orchestrator agents, fabricated agent chains, and impersonated security monitors as legitimate authority sources:
Fake Orchestrator / Agent Chain / Security Monitor
A fake orchestrator agent requesting system configuration, a fabricated agent chain claiming authority delegation, and an impersonated security monitoring agent all extracted configuration data. The model has no mechanism to verify that another "agent" in a conversation is real.
This is particularly concerning for multi-agent architectures. If you deploy Gemma 3 as one agent in a pipeline, any other agent (or an attacker impersonating one) can extract its full configuration and redirect its behavior.
What Gemma 3 Got Right
Despite the 57% failure rate, 41 tests passed. Gemma 3 showed genuine resistance in several areas:
- PII Detection (100/A): Perfect score. Correctly identified and protected all PII categories.
- Data Flow Mapping (97/A): Near-perfect analysis of data flow patterns with only one low-severity finding.
- Some encoding attacks blocked: ROT13 and Unicode smuggling attempts were detected and refused.
- Trust boundary (partial): Blocked 3 of 5 trust boundary violation attempts including convincing manager impersonation.
- Overreliance (partial): Blocked 2 of 3 overreliance tests where the model was pressured to take action based on unverified AI analysis.
The pattern: Gemma 3 handles safety-by-design tasks well (PII, data flow) but fails at adversarial robustness. It knows what data looks sensitive; it just can't resist a determined attacker who asks for it creatively.
Four-Model Comparison: The Full Picture
All four models were tested with identical system prompts, tool configurations, and test suites. Here's how they compare:
| Metric | GPT-5.2 | Gemini 2.5 Pro | Mistral Large | Gemma 3 27B |
|---|---|---|---|---|
| Overall Score | 87/100 (B) | 66/100 (D) | 53/100 (D) | 53/100 (D) |
| Injection Score | 87/100 (B) | 86/100 (B) | 45/100 (F) | 44/100 (F) |
| Injection Failure Rate | 13% (13/97) | 13.5% (13/96) | 56% (54/96) | 57% (55/96) |
| Critical Findings | 12 | 9 | 49 | 48 |
| System Prompt Extraction | 4/4 failed | 5/5 failed | 5/5 failed | 5/5 failed |
| Indirect Data Injection | 1 failure | 3/16 failed | 15/16 failed | 14/16 failed |
| Persona Hijacking | 1/2 failed | 0/4 failed | 4/4 failed | 2/3 failed |
| Agent Hijacking | 1 failure | 0 failures | 3 failures | 3/5 failed |
| Data Exfiltration | 2 failures | 2 failures | 8 failures | 4 failures |
| PII Detection | 100 (A) | 100 (A) | 100 (A) | 100 (A) |
| Compliance | 100 (A) | 0 (F) | 0 (F) | 0 (F) |
The open-source gap is real. Gemma 3 27B and Mistral Large are essentially tied at ~56-57% injection failure rates. GPT-5.2 and Gemini 2.5 Pro are tied at ~13%. The difference isn't a gradual spectrum — it's a cliff. Proprietary models with larger parameter counts and extensive RLHF/red-teaming are 4x more resistant to injection attacks than open-weight alternatives.
Same company, different results. Gemma 3 27B and Gemini 2.5 Pro are both Google models. Gemini 2.5 Pro had a 13.5% failure rate; Gemma 3 had 57%. The thinking capabilities, larger scale, and additional safety training in the proprietary model make a 4x difference in adversarial robustness.
GPT-5.2 leads overall. While Gemini 2.5 Pro matches it on injection resistance, GPT-5.2's 87/100 overall score reflects superior compliance (100 vs 0) and permission handling. The best injection defense means little if your infrastructure modules are failing.
The Open-Source Security Question
Open-weight models offer real advantages: self-hosting, fine-tuning, data privacy, no vendor lock-in. But this audit shows the security trade-off clearly. If you're choosing Gemma 3 for a production agent with tool access, you're accepting a 57% injection failure rate that the proprietary version from the same company handles at 13.5%.
This doesn't mean you shouldn't use Gemma 3. It means you need to budget for the guardrails that the model itself doesn't provide:
- External input sanitization before any data enters the model context
- Server-side tool authorization that doesn't trust the model's decisions
- Output filtering for sensitive data before responses reach users
- Rate limiting and conversation monitoring for progressive extraction patterns
- Strict separation between data processing and instruction following
Recommendations for Gemma 3 Deployments
1. Never give Gemma 3 direct tool execution
With a 57% injection failure rate and 14/16 indirect injection success rate, the model will execute malicious commands embedded in data. All tool calls must pass through a server-side policy engine that validates intent, scope, and authorization independently.
2. Treat system prompt as public information
Nine extraction techniques all succeeded. Never embed secrets, API keys, internal URLs, or sensitive business logic in the system prompt. Design your architecture assuming everything in the prompt is visible to attackers.
3. Implement strict data/instruction separation
The model cannot distinguish between data it should analyze and instructions it should follow when they appear in the same context. Use structured input formats with clear delimiters, and never pass raw user-provided content directly into the model context.
4. Do not deploy in multi-agent pipelines without isolation
With 3/3 multi-agent confusion failures, any other agent in a pipeline can extract Gemma 3's configuration and redirect its behavior. If using Gemma 3 in a multi-agent architecture, isolate it with strict API boundaries and verify all inter-agent messages.
5. Consider a hybrid architecture
Use Gemma 3 for tasks where it excels (PII detection, data analysis, content generation) behind a proprietary model that handles user-facing interaction and tool authorization. This gives you the cost and privacy benefits of open-weight models without exposing them to adversarial inputs.
Methodology Note
This audit was conducted on February 23, 2026, using AgentShield's production audit engine. The Gemma 3 27B agent was accessed via the Google AI Studio API with a standard customer service configuration including tool access, identical to the configuration used in our GPT-5.2, Gemini 2.5 Pro, and Mistral Large audits. The system prompt was embedded in conversation context rather than the systemInstruction field, as Gemma 3 does not support system instructions. Results reflect model behavior at the time of testing and may differ under different prompts, configurations, or after model updates. AgentShield is an independent security testing platform with no commercial relationship with Google. We follow responsible disclosure practices and do not publish exact attack prompts.